

Scikit-learn – Die bewährte Machine Learning Bibliothek für Python 🧠
Scikit-learn – Die bewährte Machine Learning Bibliothek für Python 🧠
Verfügbarkeit für Abholungen konnte nicht geladen werden
🧠 Was ist scikit-learn?
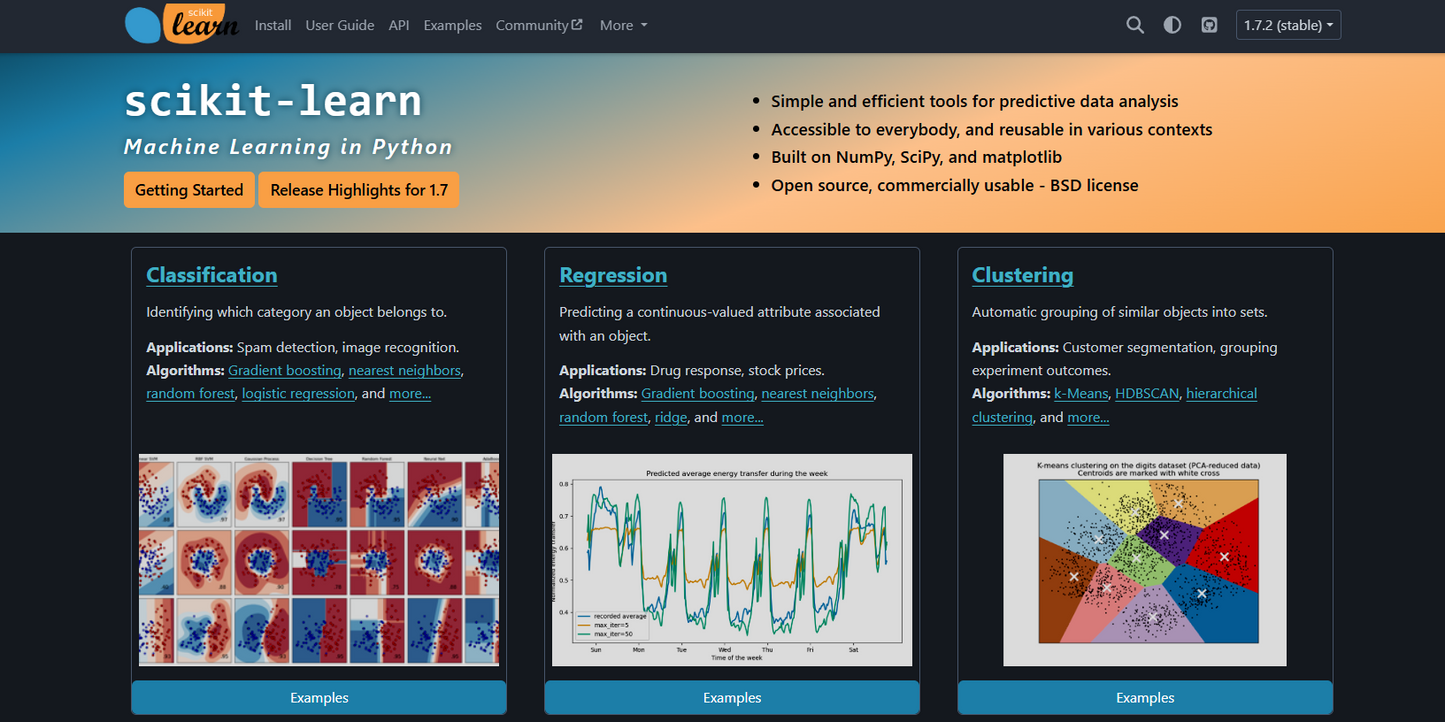
scikit-learn ist eine beliebte Open-Source Bibliothek für maschinelles Lernen in Python. Sie bietet einfache, einheitliche Schnittstellen für viele Standard-Algorithmen wie Klassifikation, Regression, Clustering und Dimensionsreduktion. Die Bibliothek baut auf NumPy und SciPy auf und wird weltweit in Forschung, Lehre und Industrie eingesetzt. Scikit-learn+2Wikipedia+2
🌟 Vorteile und Besonderheiten
-
Einfache Anwendung – gleiche API für viele Algorithmen sorgt für schnellen Einstieg IBM+2DigitalOcean+2
-
Breites Spektrum an Algorithmen – z. B. Random Forest, Support-Vector Machines, K-Means, Gradient Boosting Wikipedia+2DigitalOcean+2
-
Freie Nutzung unter BSD-Lizenz – erlaubt kommerzielle Nutzung und Anpassungen Wikipedia+3GitHub+3Scikit-learn+3
-
Aktive Community & Pflege – viele Beiträge, regelmäßige Updates, gutes Ökosystem GitHub+2Scikit-learn+2
-
Skalierbarkeit für mittlere Datenmengen – ideal für klassische ML-Aufgaben, weniger für sehr große Deep-Learning-Modelle DigitalOcean+2Wikipedia+2
🧭 Vision und Werte
scikit-learn will maschinelles Lernen zugänglich, stabil und zuverlässig machen. Durch Einfachheit und Konsistenz ermöglicht die Bibliothek, sich auf Modelle und Erkenntnisse zu konzentrieren statt auf Boilerplate-Code.
📦 Produktorganisation
-
Produktkategorie: Machine Learning Bibliothek / Framework
-
Produkttyp: Open-Source Python Modul
-
Anbieter: Community / Open-Source Projekt (u. a. Beiträge von Google, INRIA etc.) Scikit-learn+3Wikipedia+3GitHub+3
-
Komponenten / Bestandteile:
• Klassifikatoren & Regressoren
• Cluster-Algorithmen
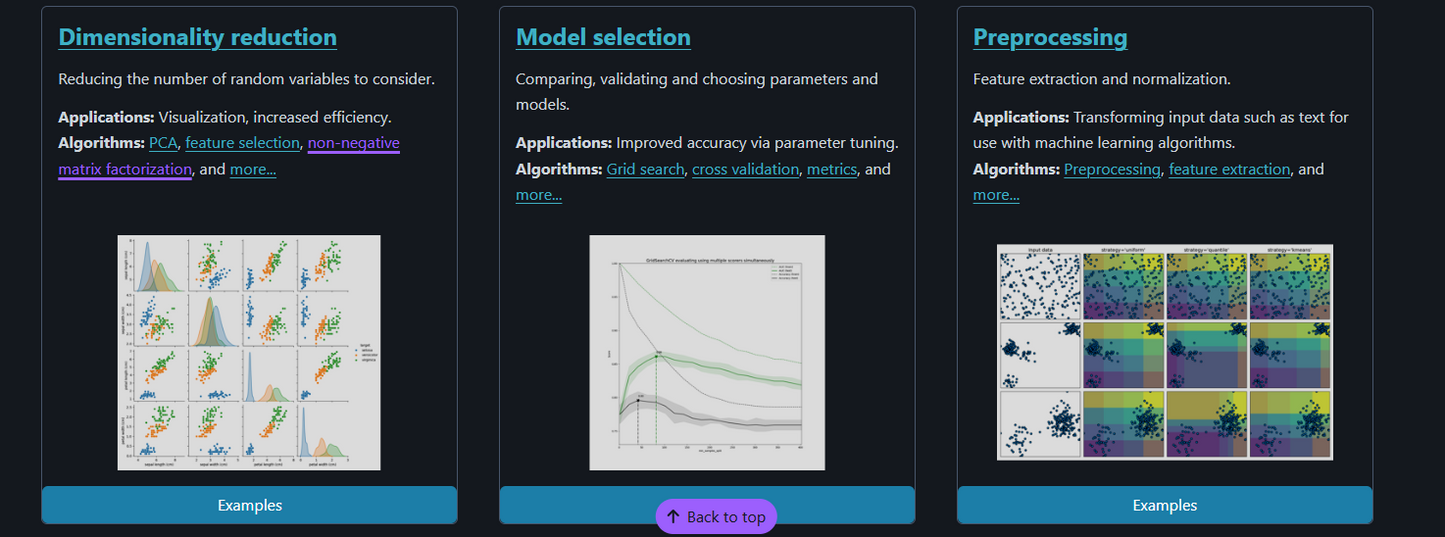
• Pipeline / Preprocessing
• Modellselektion & Hyperparameter-Tuning
• Tools zur Dimensionalitätsreduktion -
Relevante Tags: #MachineLearning 🤖 #Python 🐍 #OpenSource 🌱 #scikit-learn #DataScience #Algorithmen
🧰 Anwendungsbeispiele
-
Klassifizierung von Bildern oder Texten
-
Prognosen (z. B. Preisvorhersagen)
-
Clustering von Kundendaten
-
Datenvorverarbeitung, Feature Engineering
-
Modellvergleich mit Cross-Validation
-
Einsatz in Forschung, Prototyping und Lehre