

Scikit-learn: la biblioteca de aprendizaje automático probada para Python 🧠
Scikit-learn: la biblioteca de aprendizaje automático probada para Python 🧠
No se pudo cargar la disponibilidad de retiro
🧠 ¿Qué es scikit-learn?
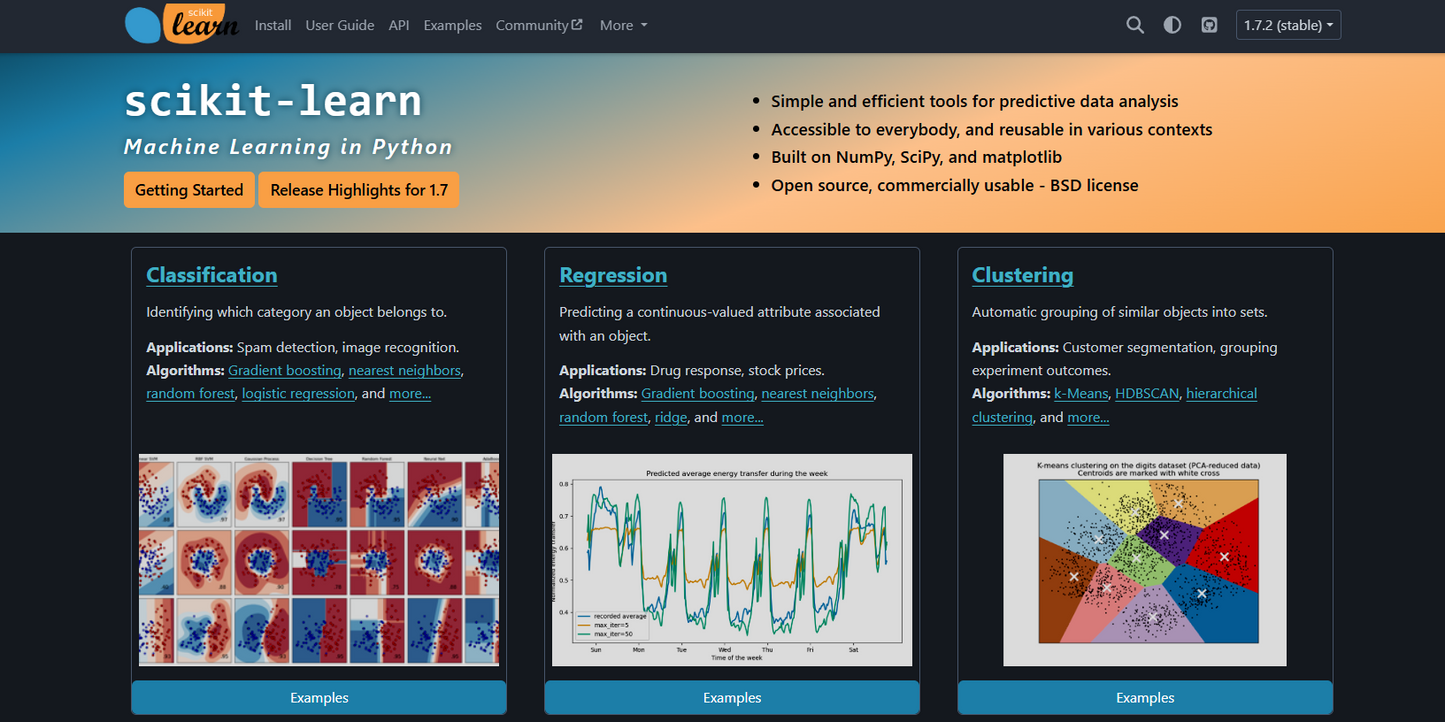
scikit-learn es una popular biblioteca de código abierto para aprendizaje automático en Python. Ofrece interfaces sencillas y unificadas para numerosos algoritmos estándar, como clasificación, regresión, agrupamiento y reducción de dimensionalidad. La biblioteca se basa en NumPy y SciPy y se utiliza a nivel mundial en investigación, educación e industria. [Scikit-learn +2 Wikipedia +2]
🌟Ventajas y características especiales
-
Fácil de usar : la misma API para muchos algoritmos garantiza un inicio rápido IBM +2 DigitalOcean +2
-
Amplia gama de algoritmos , por ejemplo, Random Forest, máquinas de vectores de soporte, K-Means, Gradient Boosting Wikipedia +2 DigitalOcean +2
-
Uso gratuito bajo licencia BSD : permite uso comercial y modificaciones . Wikipedia +3 GitHub +3 Scikit-learn +3
-
Comunidad activa y mantenimiento : muchas contribuciones, actualizaciones periódicas, buen ecosistema GitHub +2 Scikit-learn +2
-
Escalabilidad para conjuntos de datos medianos : ideal para tareas clásicas de aprendizaje automático, pero menos para modelos de aprendizaje profundo muy grandes . DigitalOcean +2 Wikipedia +2
🧭 Visión y Valores
El objetivo de scikit-learn es que el aprendizaje automático sea accesible, estable y fiable. Gracias a su simplicidad y consistencia, la biblioteca permite a los usuarios centrarse en modelos e información en lugar de en código repetitivo.
📦 Organización del producto
-
Categoría de producto : Biblioteca/Marco de aprendizaje automático
-
Tipo de producto : Módulo Python de código abierto
-
Proveedor : Comunidad / Proyecto de código abierto (incluidas contribuciones de Google, INRIA, etc.) Scikit-learn +3 Wikipedia +3 GitHub +3
-
Componentes / piezas :
• Clasificadores y regresores
• Algoritmos de cluster
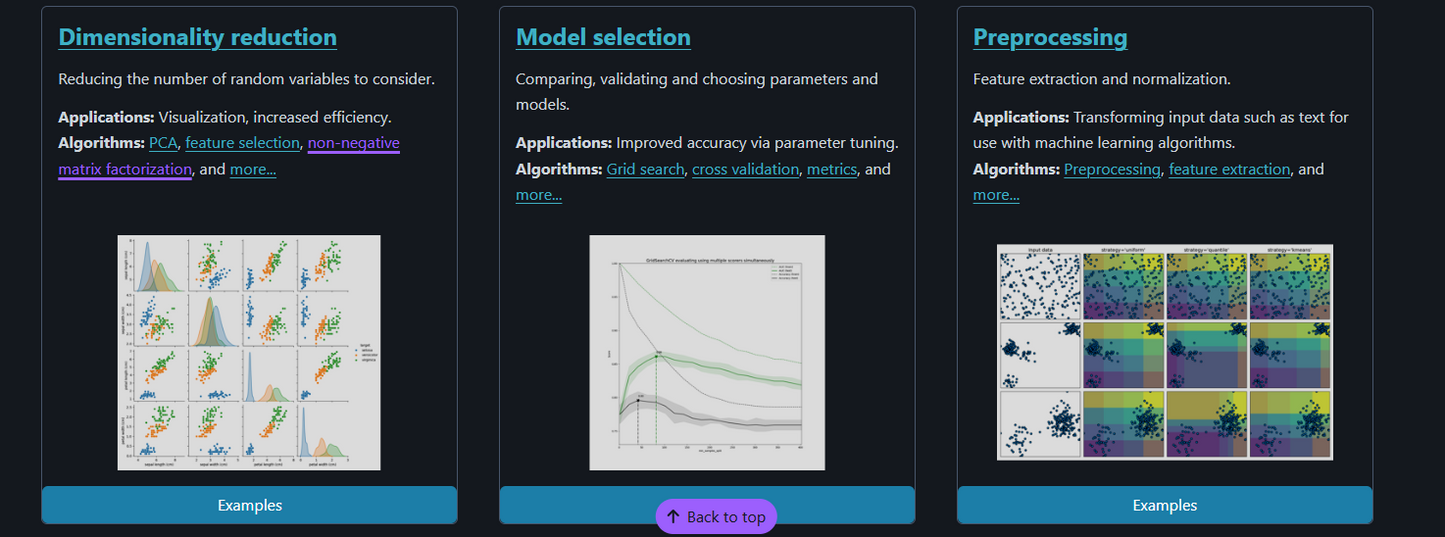
• Tubería / Preprocesamiento
• Selección de modelos y ajuste de hiperparámetros
• Herramientas para la reducción de dimensionalidad -
Etiquetas relevantes : #MachineLearning 🤖 #Python 🐍 #OpenSource 🌱 #scikit-learn #DataScience #Algoritmos
🧰 Ejemplos de aplicación
-
Clasificación de imágenes o textos
-
Pronósticos (por ejemplo, predicciones de precios)
-
Agrupación de datos de clientes
-
Preprocesamiento de datos, ingeniería de características
-
Comparación de modelos con validación cruzada
-
Uso en investigación, creación de prototipos y docencia.