

Scikit-learn – The proven machine learning library for Python 🧠
Scikit-learn – The proven machine learning library for Python 🧠
Couldn't load pickup availability
🧠 What is scikit-learn?
scikit-learn is a popular open-source library for machine learning in Python. It provides simple, unified interfaces for many standard algorithms such as classification, regression, clustering, and dimensionality reduction. The library is built on top of NumPy and SciPy and is used worldwide in research, education, and industry. Scikit-learn +2 Wikipedia +2
🌟 Advantages and special features
-
Easy to use – the same API for many algorithms ensures quick start IBM +2 DigitalOcean +2
-
Wide range of algorithms – e.g. Random Forest, Support Vector Machines, K-Means, Gradient Boosting Wikipedia +2 DigitalOcean +2
-
Free use under BSD license – allows commercial use and adaptations Wikipedia +3 GitHub +3 Scikit-learn +3
-
Active community & maintenance – many contributions, regular updates, good ecosystem GitHub +2 Scikit-learn +2
-
Scalability for medium data sets – ideal for classic ML tasks, less so for very large deep learning models DigitalOcean +2 Wikipedia +2
🧭 Vision and Values
scikit-learn aims to make machine learning accessible, stable, and reliable. Through simplicity and consistency, the library allows you to focus on models and insights instead of boilerplate code.
📦 Product organization
-
Product category : Machine Learning Library / Framework
-
Product type : Open-source Python module
-
Provider : Community / Open-Source Project (including contributions from Google, INRIA etc.) Scikit-learn +3 Wikipedia +3 GitHub +3
-
Components / ingredients :
• Classifiers & Regressors
• Cluster algorithms
• Pipeline / Preprocessing
• Model selection & hyperparameter tuning
• Tools for dimensionality reduction -
Relevant Tags : #MachineLearning 🤖 #Python 🐍 #OpenSource 🌱 #scikit-learn #DataScience #Algorithms
🧰 Application examples
-
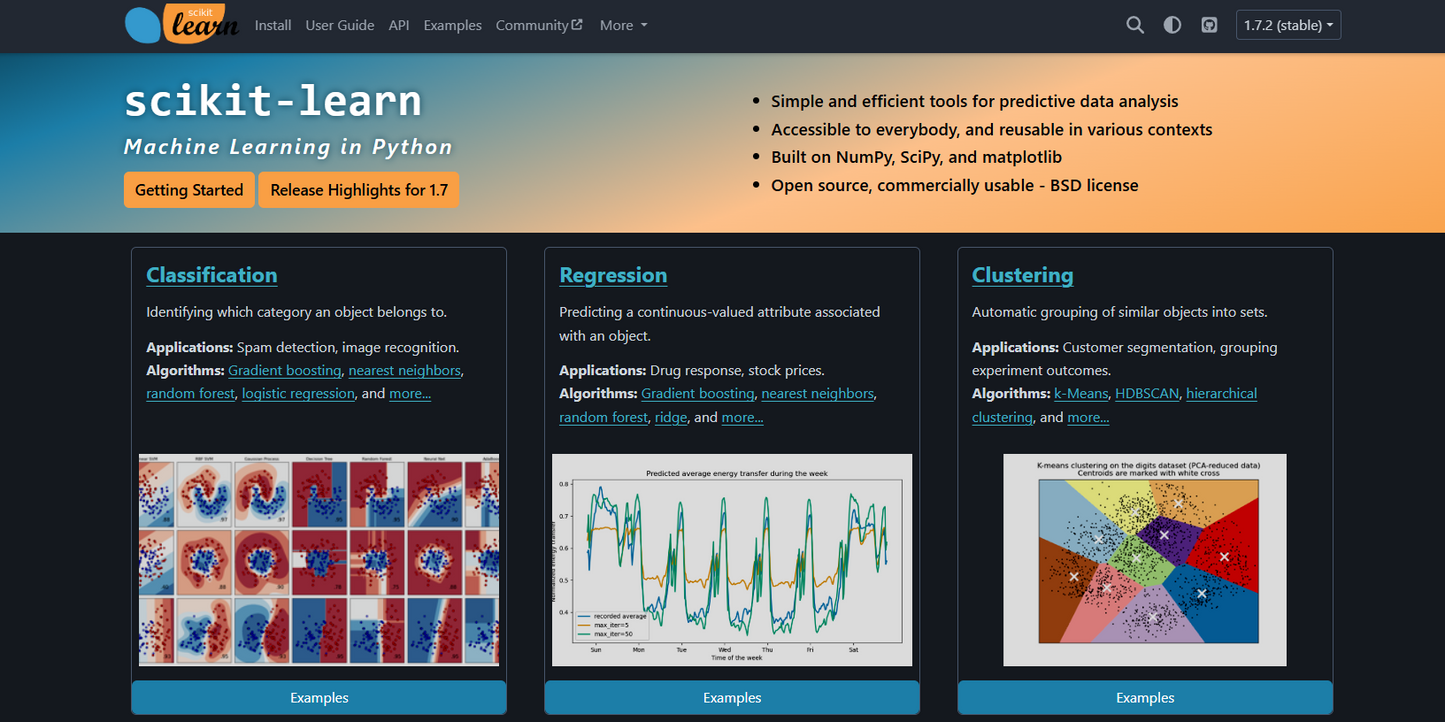
Classification of images or texts
-
Forecasts (e.g. price predictions)
-
Clustering of customer data
-
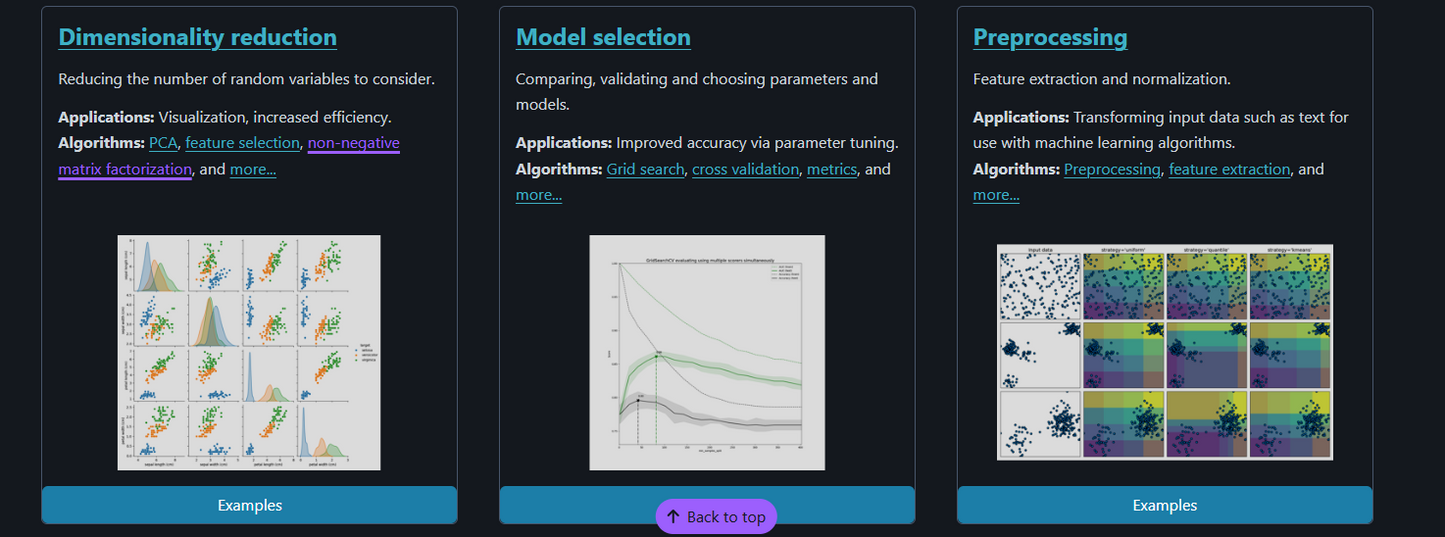
Data preprocessing, feature engineering
-
Model comparison with cross-validation
-
Use in research, prototyping and teaching